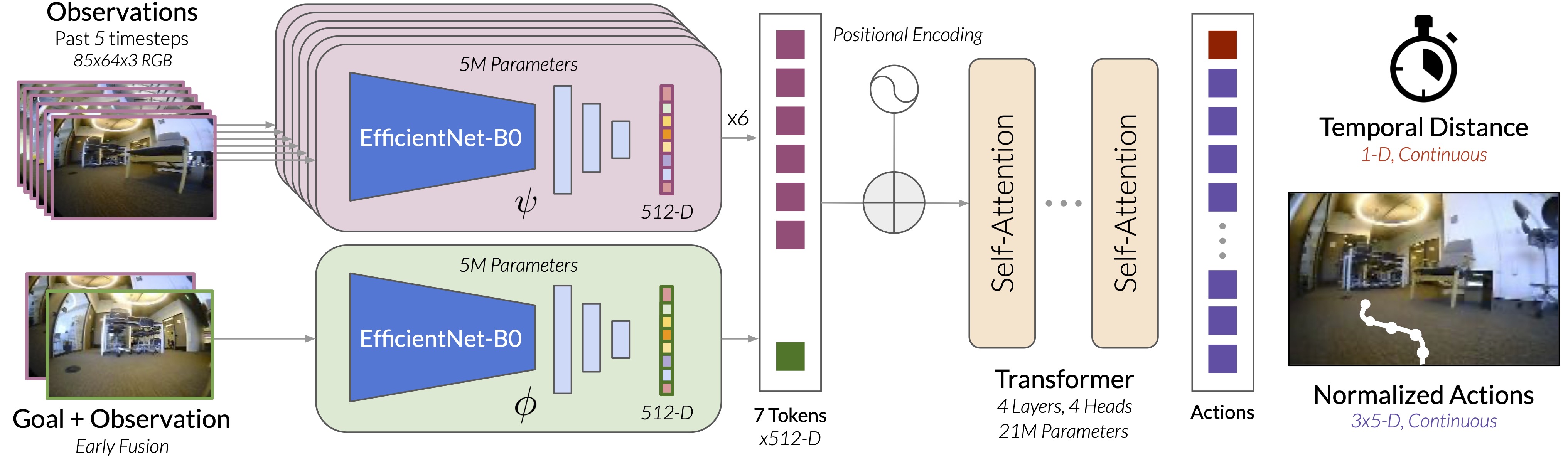
ViNT Architecture
ViNT uses a Transformer-based architecture to encode (current and past) visual observations and goals using an EfficientNet CNN, and predicts temporal distance and normalized actions in an embodiment-agnostic manner.
Search Overview
ViNT can explore previously unseen environments by employing a topological graph-based global planner. An image-to-image diffusion model proposes diverse exploration targets which are spatially grounded using ViNT (yellow), and scored using a goal-directed heuristic h. Subgoals are added to the topological graph and executed using the ViNT policy.

Long-Range Navigation with Context
ViNT can solve long-range navigation problems when equipped with a long-range heuristic. Here, we show ViNT solving a 1.5km navigation problem in a previously unseen environment, using a heuristic that estimates the distance to the goal using a pre-trained depth model.
To further show the different exploration behaviors supported by ViNT, here we deploy a locobot to explore an office floor from the same starting point but with two different position goals to guide the search. Starting from the same position, the different goals lead the robot to two different parts of the building, and both trajectories succeed in reaching their goals.
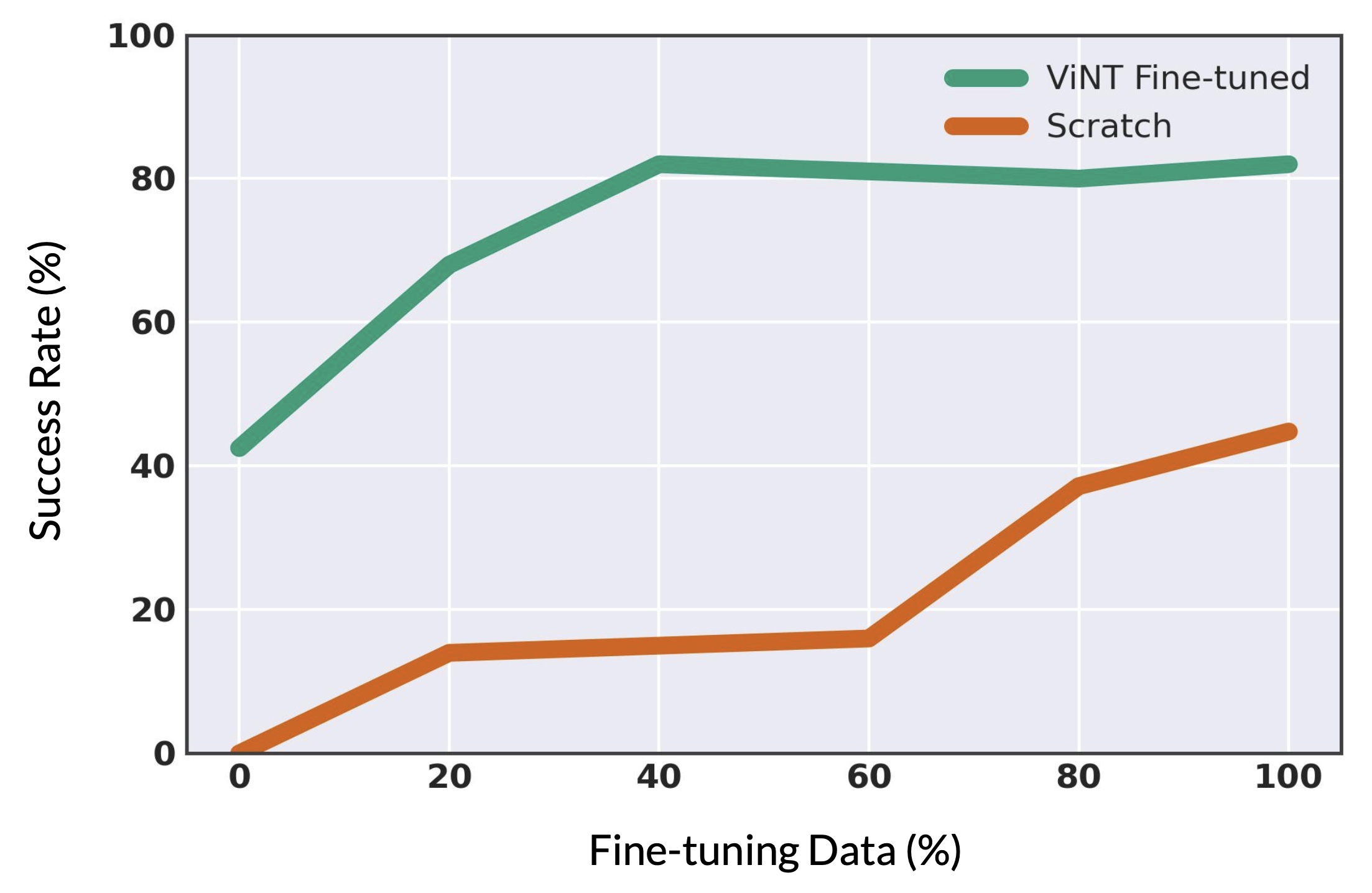
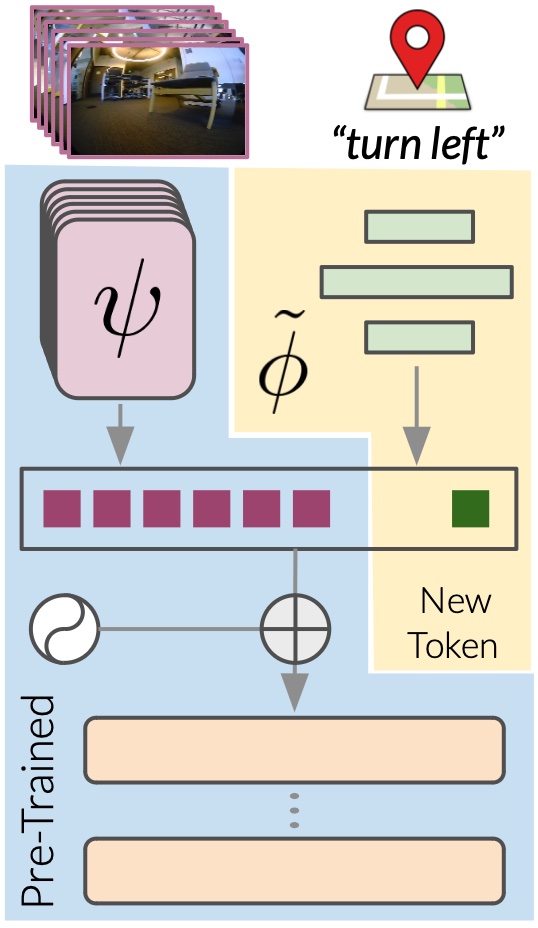
Adaptation to Downstream Tasks
Beyond its core functionality as an image goal-conditioned model, the strong navigational priors learned by ViNT can be adapted to a variety of downstream tasks, beyond navigating to image goals, by fine-tuning part or all of the model in novel environments or with new modalities of data.
Emergent Behaviors
Implicit Navigation Preferences
ViNT exhibits implicit preferences for following paved roads and narrow hallways while searching previously unseen environments, enabling efficient exploration.
Robustness to Dynamic Pedestrians
ViNT can successfully navigate around a crowd of dynamic pedestrians and reach the goal behind them, despite its simple self-supervised training objective.
BibTeX
@article{shah2023vint,
author = {Dhruv Shah and Ajay Sridhar and Nitish Dashora
and Kyle Stachowicz and Kevin Black and Noriaki Hirose and Sergey Levine},
title = {{ViNT: A Foundation Model for Visual Navigation}},
journal = {arXiv pre-print},
year = {2023},
url = {https://arxiv.org/abs/2306.14846},
}